Main source
Mysterious and valuable part!

دیدنش با چشم چون ممکن نبود - اندر آن تاریکیش کف میبسود
مولانا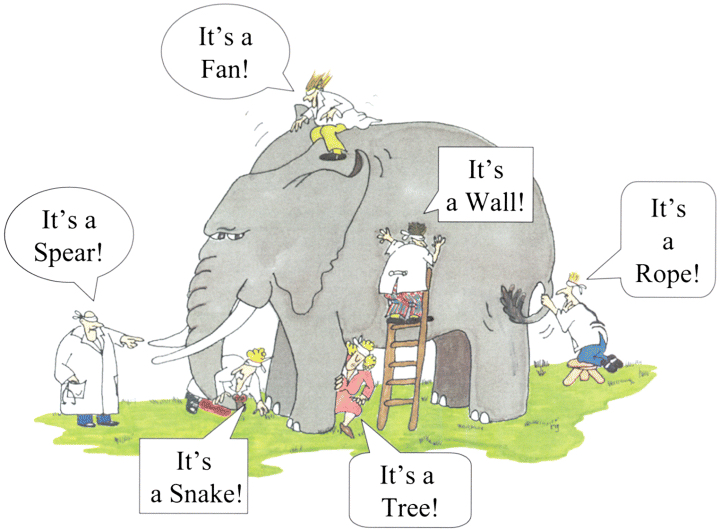
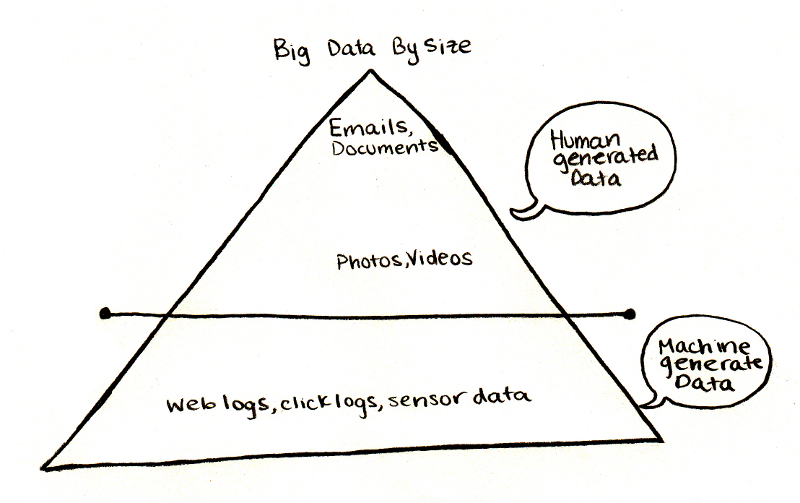
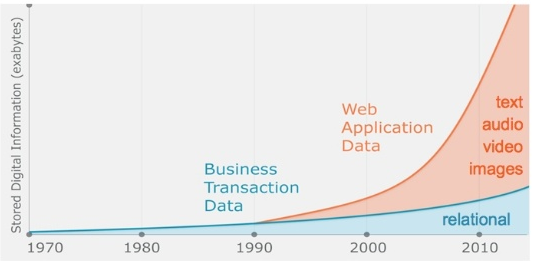
Big Data, Hadoop & more


Sources (Users, Clients), Forms



MySQL, MariaDB, Access, SQL Server, Oracle
Time out on expensive servers...
You must change your technologies


Implicit and Explicit

Share ...!?
Did you just pause that?

Share, view, follow

Clicks
Applications
Servers (Web, Email, Proxy, ...)
Systems journalct
Hardwares Access point
Life
Mysterious and valuable part!

A simple tweet


Low resistance but inexpensive and infinite

Organizations
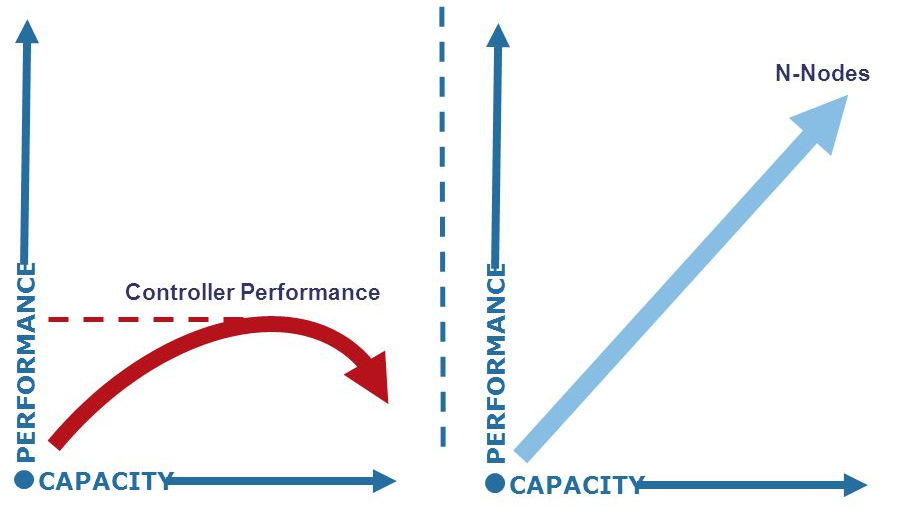
Bottlenecks like: Disk IO, load avg
No matter how much memory I have...

Now we know what we are looking for!
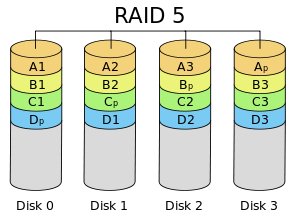

GFS, ???

Apache Lucene (IR)
Apache Nutch (Web Crawler)

It's just a framework, C4.5



An opensource software platform for distributed storage and distributed processing of very large data sets on computer clusters built from commodity hardware
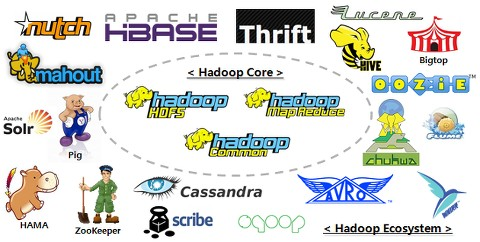
GFS, MapReduce
HDFS, Hadoop MapReduce
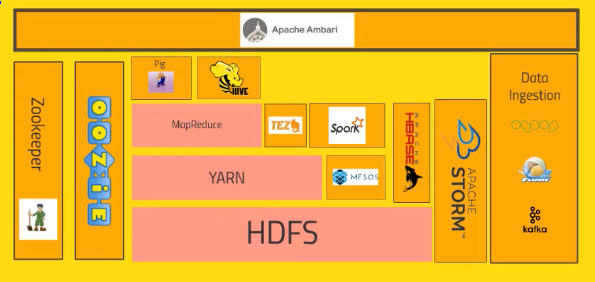 HDFS |
YARN |
MapReduce |
Pig |
Hive |
TEZ |
Storm |
Spark |
oozie |
Zookeeper |
Others
HDFS |
YARN |
MapReduce |
Pig |
Hive |
TEZ |
Storm |
Spark |
oozie |
Zookeeper |
Others
Allows us to distribute the storage
All hard drives look likes a single huge hard disk
Keeps copy of data
No single point of failure
Back
Manage the resouces
What get to run tasks and when
Which node is available
We build applications on top of it
Back
Got remvoed from YARN
Back
No java, Python? Scripting language like SQL
Transforms the script to something than can be run on MapReduce
SQL
Makes the data to look like a RDBMS
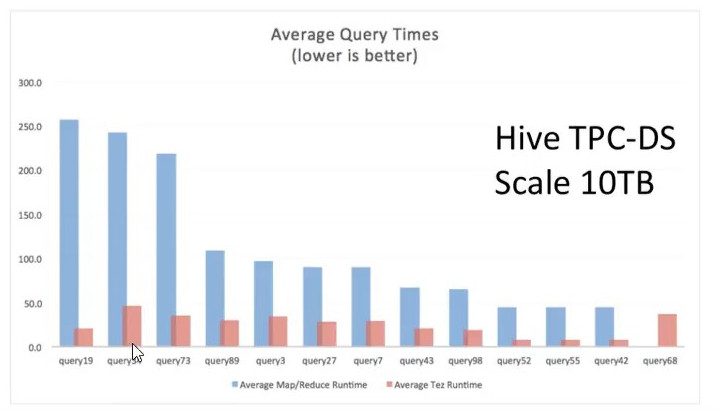
Hive on TEZ is faster than MapReduce
BackSitting at same level of MapReduce on top of YARN Or MESOS Python, Java, Scala Fast Active development Handle SQL Query Machine learning Handle Stream data
BackProcessing streaming data Sensors, Logs Spark streaming does the same thing Update machine learning model Update data as it comes
Back
Complicated steps
Load to hive, Query using spark then transform to HBASE.
Cordinates everything on clusters
Which node is up or down
Many of these apps relay on zookeeper
Turn into hadoop, talks to ODBS JDBC
Transport Web logs into hadoop (spark, storm)
Like flume but more general, cluster of PC or webservers or whatever to broadcast into Hadoop cluster.
Back

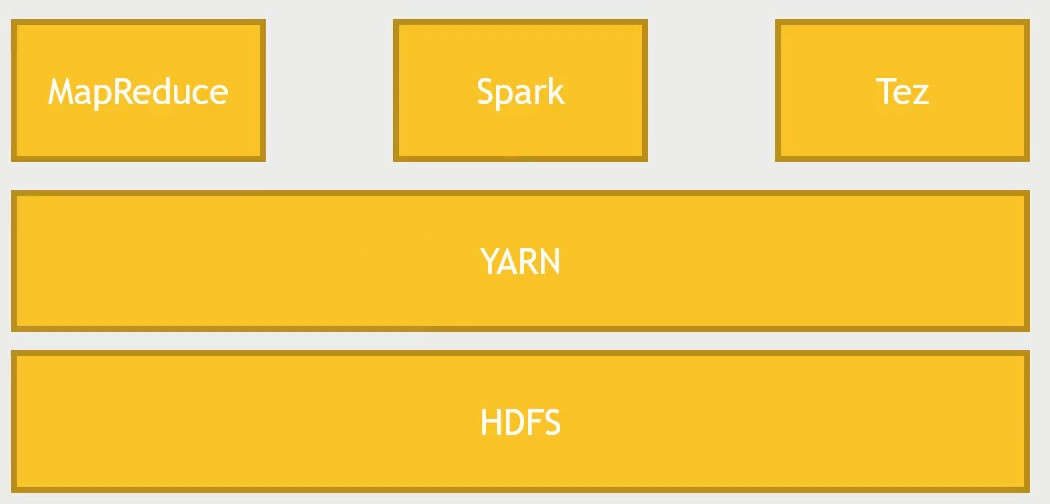
Complicated stuff, we don't have to worry about the details
Hadoop V2 separated from MapReduce
Run MapReduce alternatives on it (TEZ)
Idea? split the computation across the cluster
Maintain data locality (Integrated with HDFS, where data lives)
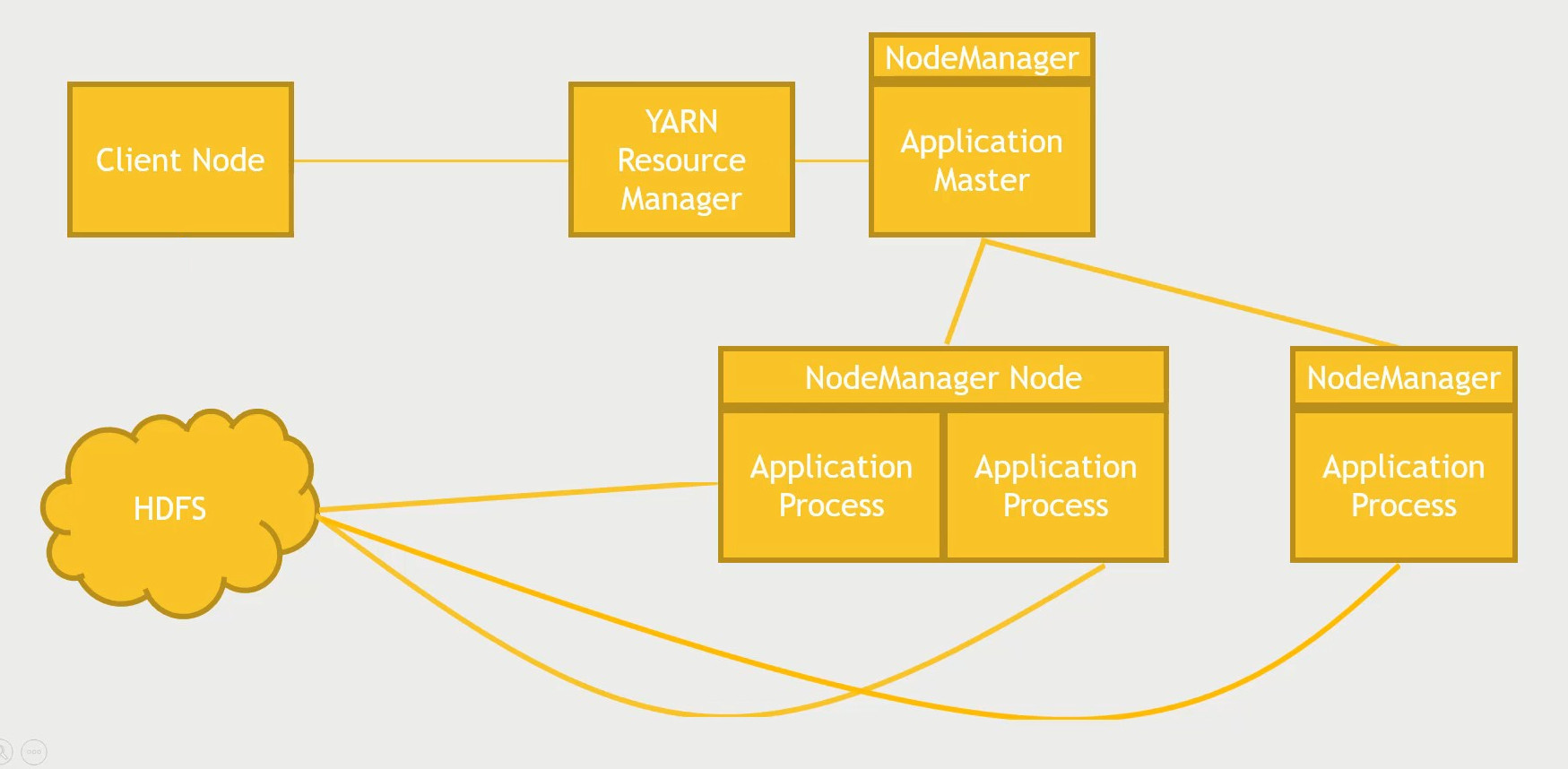
We can have multiple resource manager

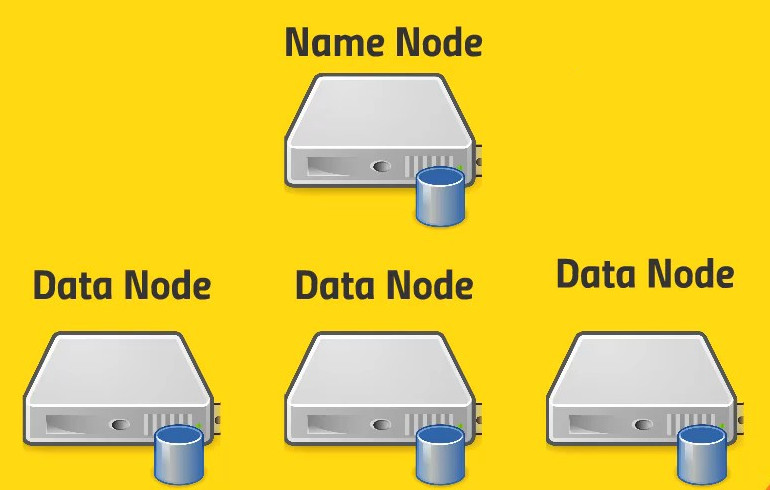
Allow our big data to be stored across entire cluster in distributed and reliable manner.
Handling large files
Breaking data into blocks - 128 MB
Keeps multiple copies of these blocks (Clever way)
Allow us to use regular computers (No special hardware needed)
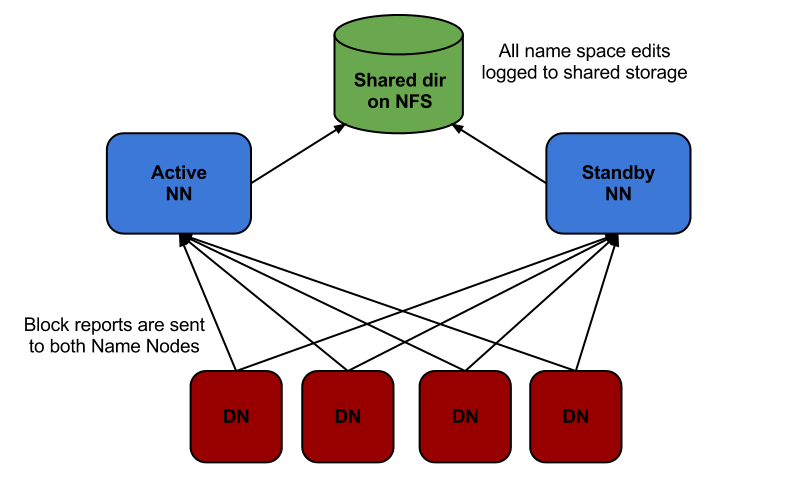
Client <--- > Zookeeper
One namenode is active at a time
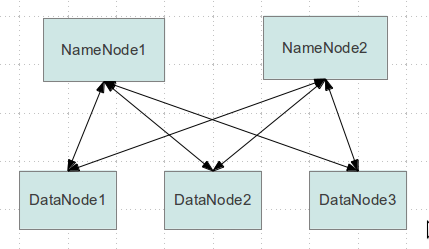
Sub Directories -> namespace Volume -> each namenode manage one namespace volume (dumpe2fs)


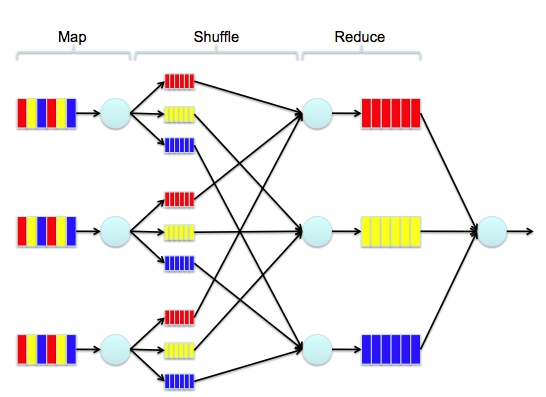
Map: Transfer Data that we care about
Shuffle and sort
Reduce: Aggregate Data

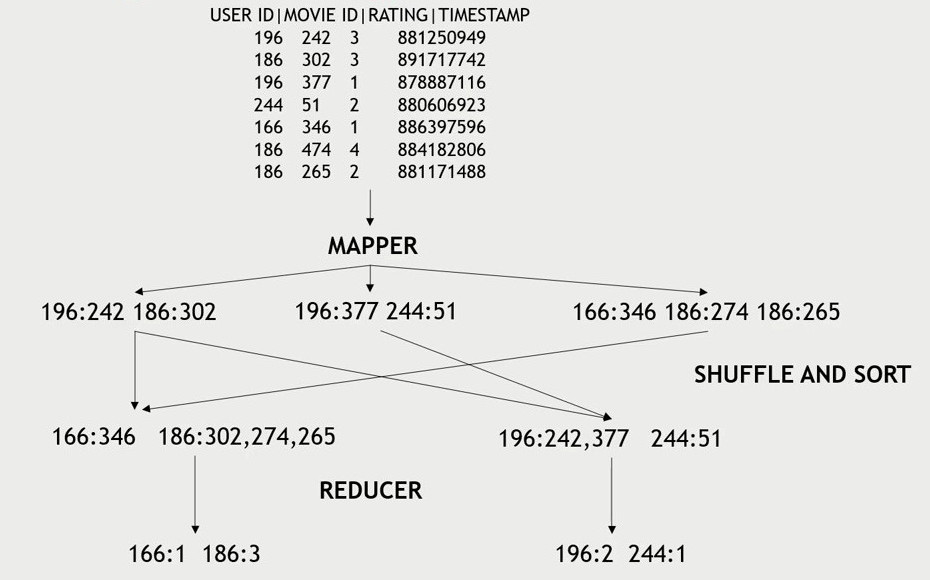
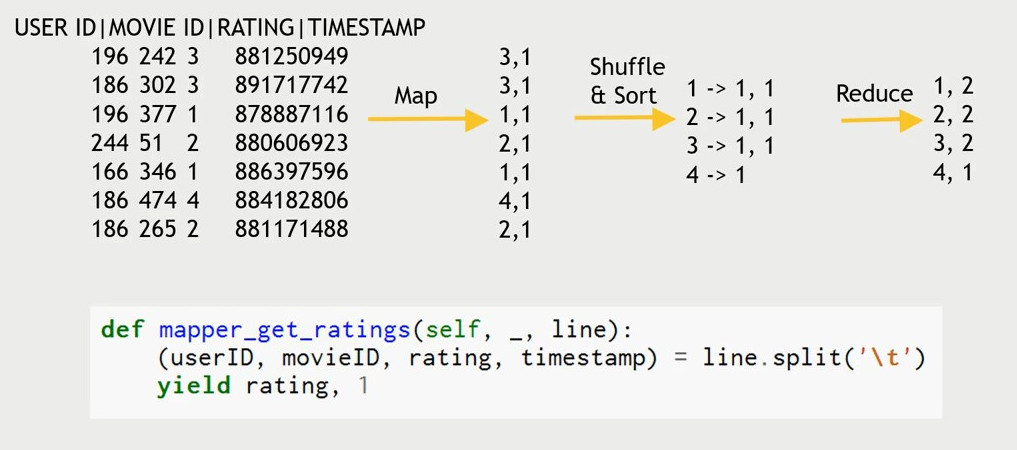
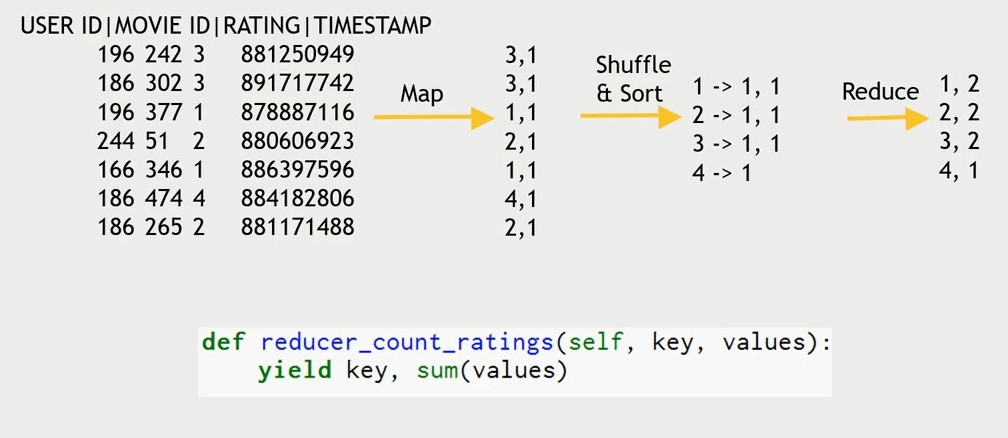
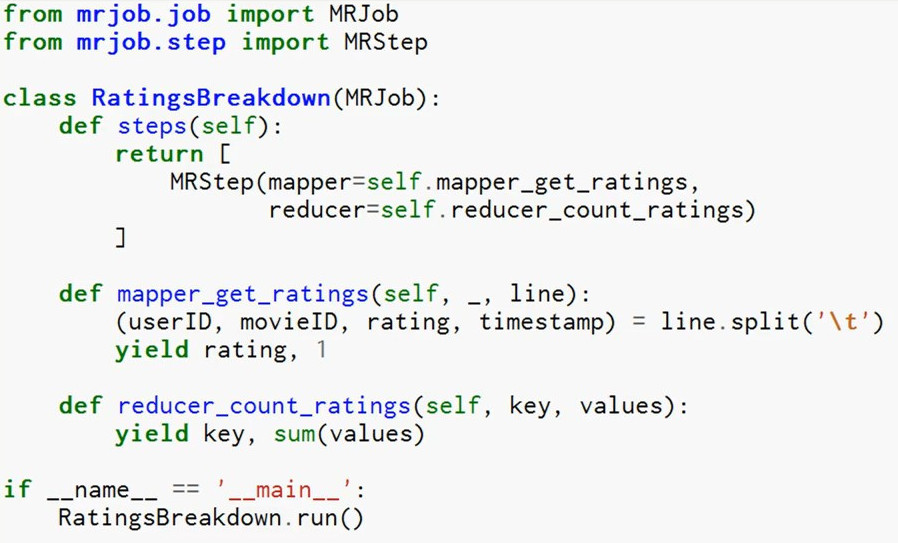

Forums, Messengers, Comments, Q/A, Reviews